Пора бы уже и поделиться чем-нибудь свеженьким.
В общем задача ( для меня свежая, для кого-то может и не очень ) :
а) есть сервер с базой данных
б) мобильное приложение, которое должно кэшировать часть серверной базы данных
в) доступ к данным возможен через веб сервис в виде csv / xml / json
Требуется реализовать импорт базы данных наиболее эфективным способом, поскольку данных достаточно много.
Итак, поехали ...
Первое с чего я решил начать, это выборка данных через веб сервис. В каком виде брать данные из веб сервиса ? Долго не думая над этим вопросо я решил пройти по протоптоной дорожке и вытаскивать данные в JSON. Почему ? Всё очень просто. Во-первых, Android SDK имеет встроенную поддержку JSON с помощью org.json библиотеки. Во-вторых, работать с JSON, как по мне, несколько удобнее чем с XML или CSV. И в третьих он компактнее чем XML, хотя и не настолько компактный как CSV.
В общем первая реализация не заставила себя долго ждать и получилось что-то вроде:
HttpClient client = new DefaultHttpClient();
HttpGet request = new HttpGet(url.toString());
HttpResponse response = client.execute(request);
// Pull content stream from response
HttpEntity entity = response.getEntity();
InputStream inputStream = entity.getContent();
ByteArrayOutputStream content = new ByteArrayOutputStream();
// Read response into a buffered stream
int readBytes = 0;
byte[] buffer = new byte[BUFFER_SIZE];
while ((readBytes = inputStream.read(buffer)) != -1) {
content.write(buffer, 0, readBytes);
}
String plain = new String(content.toByteArray());
JSONArray data = new JSONArray(plain);
Отточеная до автоматизма тривиальность не предвещала никаких сложностей. Но увы, как это часто бывает всё не так просто как кажется на первый взгляд.Пробный запуск и приложение вылетает с OutofMemoryError. Оказалось, что данных сервер выдаёт порядка 4,3Мб и при очередном копировании данных в памяти виртуальная машина выкидывает исключение. На каком именно копировании я не разбирался. Всего их получается три inputStream -> content, content -> plaint, plain -> data и в памяти в один момент могут держаться все четыре копии данных, что порядка 16Мб. Для меня всё же остаётся не совсем ясным почему возникает это исключение, поскольку на моём устройстве 576 Мб оперативки из которых 256 Мб обычно свободны. Ну да ладно. Зато это послужило хорошим поводом чтобы разобраться.
Первоё с чего я с коллегой начал - это постраничная выборка данных, так чтобы за один раз получать ограниченный набор данных и после его успешной обработки, тянуть следующий.
В итоге в приложение добавился цикл, а в url дополнительный параметр указывающий номер первой записи в наборе и размер страницы.
Попробовал - заработало. Ура !
Самое время заняться локальной базой данных и её наполнением. Вот примерный код:
for (int i = 0; i < response.length(); i++) {
JSONObject item = response.getJSONObject(i).getJSONObject("item");
Point point = Point.fromJson(item);
ContentValues values = new ContentValues();
values.put(KEY_POINT_ID, object.getId());
values.put(KEY_POINT_NAME, object.getName());
values.put(KEY_POINT_LAT, object.getLat());
values.put(KEY_POINT_LON, object.getLon());
values.put(KEY_POINT_TYPE, object.getType());
values.put(KEY_POINT_UPDATE_TIME, object.getUpdateTime());
db.insert(TABLE_POINT, null, values);
}
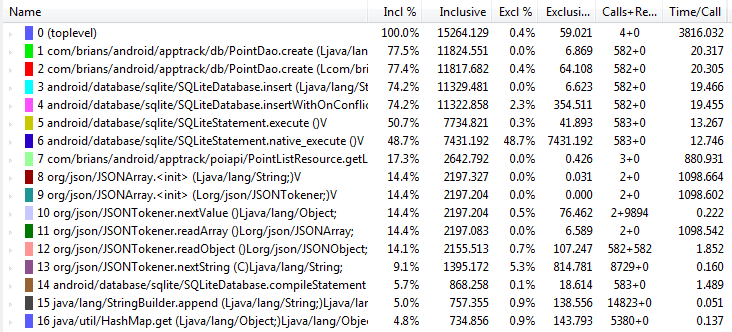
Запускаем - замечательно, всё работает как в сказке с первой попытки. Только вот как-то долго... Прошло минуты две, а обработаны меньше четверти данных... Вряд-ли у пользователей хватит терпения ждать 10 минут, пока загрузится приложение. Да и как-то не гуманно это что-ли, так что начинаем анализировать на что тратится так много времени. Для этого под Android есть специальная тулза traceview и Debug.startMethodTracing / Debug.stopMethodTracing в помощь. Важный момент - размер .trace - файла по умолчанию 8 Мб, что исчерпывается быстро. Поэтому я установил его побольше и ограничить импорт выборкой одной страницы в 582 записи. Оборачиваем интересующий нас код вот так:
Debug.startMethodTracing("myapp", 20 * 1024 * 1024);
// ... сдесь идёт код импорта данных ...
Debug.stopMethodTracing();
Снова запускаем и по завершению выполнения находим myapp.trace в корне /sdcard на телефоне. Теперь для анализа "сырых" данных из этого файла запускаем:
traceview <путь-к-папке>/myapp
do {
HttpClient client = new DefaultHttpClient();
HttpGet request = new HttpGet(url.toString());
HttpResponse response = client.execute(request);
// Pull content stream from response
HttpEntity entity = response.getEntity();
InputStream inputStream = entity.getContent();
JsonFactory f = new JsonFactory();
JsonParser jp = f.createJsonParser(inputStream);
if (jp.nextToken() == JsonToken.VALUE_NULL) {
break;
}
while (jp.nextToken() != JsonToken.END_ARRAY) {
Point point = null;
while (jp.nextToken() != JsonToken.END_OBJECT) {
String fieldname = jp.getCurrentName();
jp.nextToken(); // move to value, or
// START_OBJECT/START_ARRAY
if ("item".equals(fieldname)) { // contains an object
point = pointFromJson(jp);
} else {
throw new IllegalStateException("Unrecognized field '" + fieldname + "'!");
}
}
if (point != null) {
db.getPointDao().create(point);
}
}
jp.close();
А, вот как изменилась статистика:

// Prepare insert statement.
SQLiteStatement insert = db.compileStatement(INSERT_STATEMENT);
db.beginTransaction();
try {
while (scanner.hasNextLine()) {
String line = scanner.nextLine();
String[] columns = line.split(";");
try {
if (columns.length == 7) {
insert.clearBindings();
// Important ! Order of the fields in the statement
// should be the same like in CSV input.
for (int i = 0; i < 7; i++) {
insert.bindString(i + 1, columns[i]);
}
insert.execute();
result++;
}
} catch (Exception e) {
Log.e("AppTrack", Log.getStackTraceString(e));
}
}
db.setTransactionSuccessful();
} finally {
db.endTransaction();
}
Итак, после всех-всех оптимизаций импорт данных занимает менее 1,5 мин вместо изначальных 10 мин. Кроме этого данные не копируются несколько раз в памяти, что существенно снижает нагрузку на сборщик мусора и виртуальную машину.
Вот такой небольой case study. Надеюсь кому-нибудь пригодится. Если что - пишите в коменты.
Super
ReplyDelete